Metrics explanation:
• Steps↓: The average number of actions required to complete a task. Lower values
indicate higher efficiency.
• Step Time (s)↓: The average time taken for each action (step) during task execution.
Lower values indicate faster steps.
• Tokens (k)↓: The total number of tokens used by the language model during task
execution. Fewer tokens indicate better resource efficiency.
• SR (Success Rate)↑: The percentage of tasks successfully completed. Higher values
indicate better performance.
• Task Time↓: The total time taken to complete a task. Lower values mean faster task
completion.
| Method |
Memory Type |
Action Space |
Steps↓ |
Step Time (s)↓ |
Tokens (k)↓ |
SR ↑ |
| GPT-4o (Baseline) |
None |
Basic |
10.8 |
26 |
6.72 |
16.9% |
| Element |
Basic |
9.3 |
24 |
8.46 |
69.7% |
| AppAgentX |
Chain |
Basic |
9.1 |
23 |
9.26 |
70.8% |
| Chain |
Basic+Evolve |
5.7 |
16 |
4.94 |
71.4% |
Table 1: Analysis of Different Components in AppAgentX. This table compares the
performance differences
resulting from the different designs with the baseline. Both our memory design and evolution mechanism
can
improve success rate and efficiency.
| Benchmarks |
Task Num. |
Framework |
Task Time↓ |
Tokens (k)↓ |
SR↑ |
| DroidTask |
158 |
AppAgent |
106.24 |
11.5 |
46.3% |
| AppAgentX |
56.29 |
5.1 |
88.2% |
| MobileBench (SAST) |
332 |
AppAgent |
150.24 |
7.6 |
72.6% |
| AppAgentX |
42.38 |
5.4 |
86.1% |
Table 2: Comparison with AppAgent on Large Benchmarks. This table evaluates the
efficiency and accuracy of different frameworks on benchmarks containing a large number of tasks. In the
MobileBench, SAST (Single-App-Single-Task) refers to a real dataset containing only a single task
description.
| LLM |
Previous Sota |
AppAgentX |
| Gemini-1.5-Pro |
25.6 |
12.4 |
| Claude-3.5 |
38.4 |
11.4 |
| GPT-4o |
43.5 |
17.5 |
Table 3: Comparison of Average Execution Time per Step. This table presents the average
execution time
(seconds ↓) across different LLMs and frameworks.
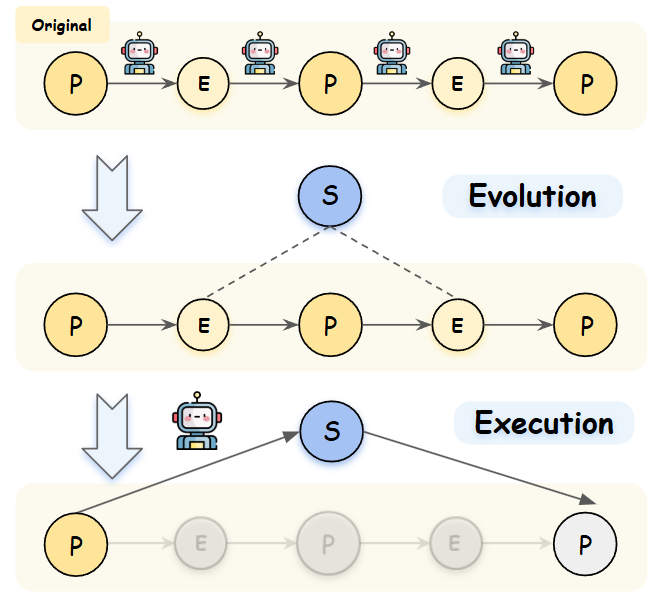
We propose an evolving GUI agent framework that enhances efficiency and intelligence by abstracting
high-level actions
from execution history. Unlike rule-based automation, our approach generalizes task execution by
compressing repetitive operations,
balancing intelligent reasoning with efficient execution. A chain-based knowledge framework enables
continuous behavior refinement,
improving adaptability and reducing redundancy. Exper- iments show our framework outperforms existing
methods in accuracy and efficiency.